分布式數據庫在數據處理與存儲支持服務中的應用 海量數據存儲與實時查詢的實現
在當今數據爆炸的時代,傳統的數據存儲和查詢架構面臨著前所未有的挑戰。隨著企業數據量的指數級增長,如何高效地存儲海量數據并實現毫秒級的實時查詢,已成為支撐業務決策與用戶體驗的關鍵。分布式數據庫應運而生,它通過將數據分散存儲在多臺獨立的服務器上,構建了一個高度可擴展、高可用且高性能的數據處理與存儲支持服務體系。
一、 分布式數據庫的核心優勢:構建彈性數據基石
分布式數據庫的核心思想是“分而治之”。它將一個龐大的數據集分割成多個較小的片段(分片),并將這些分片分布到網絡中的多個物理節點上進行存儲和處理。這種架構帶來了多重核心優勢:
- 海量存儲與線性擴展:存儲容量和處理能力可以通過簡單地增加節點來近乎線性地提升,輕松應對從TB到PB級別的數據增長,滿足長期數據存儲與積累的需求。
- 高可用與容錯性:數據通常會在多個節點上保存副本。當某個節點發生故障時,系統可以自動將請求路由到存有數據副本的其他健康節點,確保服務不中斷,為關鍵業務提供7x24小時的數據支持服務。
- 高性能并行處理:查詢和計算任務可以被分解,并在多個節點上并行執行,極大縮短了響應時間,為實現復雜分析查詢和實時數據檢索提供了可能。
二、 實現海量數據存儲的關鍵技術
要實現穩定可靠的海量數據存儲,分布式數據庫依賴一系列關鍵技術:
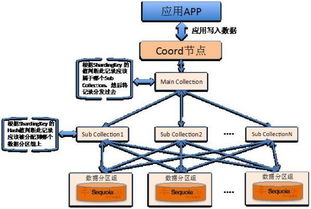
- 數據分片策略:這是分布式存儲的基石。常見的策略包括基于哈希值、數據范圍或列表的分片方式。合理的分片策略能確保數據均勻分布,避免“熱點”節點,并支持高效的數據路由。
- 多副本與一致性協議:為保證數據可靠性,同一份數據會在多個節點(通常為3個副本)存儲。這引入了數據一致性問題。系統通過Raft、Paxos等分布式一致性協議,確保在發生寫入或副本同步時,所有副本最終保持一致狀態,在可用性與一致性之間取得最佳平衡。
- 分布式事務管理:跨多個分片的數據更新操作需要分布式事務來保證ACID特性(原子性、一致性、隔離性、持久性)。兩階段提交(2PC)等協議被廣泛應用,新型數據庫也通過優化鎖機制和采用多版本并發控制(MVCC)來提升事務處理效率。
三、 支撐實時查詢的架構與優化
實時查詢要求系統在極短時間內返回精確或聚合結果,這對分布式架構的查詢引擎提出了極高要求。
- 分布式查詢引擎:作為系統的“大腦”,它接收用戶查詢請求,生成最優的分布式執行計劃。該計劃將查詢拆解為一系列能在各個數據節點上并行執行的子任務,最后匯總中間結果并返回給用戶。
- 全局索引與二級索引:為加速查詢,除了本地索引,分布式數據庫還支持構建跨節點的全局索引。查詢可以首先通過索引快速定位到數據所在的分片,而非掃描所有節點,這是實現低延遲查詢的關鍵。
- 內存計算與緩存層:將熱點數據或中間結果緩存在內存中,可以極大減少磁盤I/O。許多分布式數據庫集成了內存計算引擎,并利用Redis等外部緩存作為補充,為實時性要求最高的場景提供亞秒級響應。
- 近實時數據攝入:為了支持對最新數據的查詢,系統需要高效的數據攝入管道。通過Change Data Capture(CDC)技術實時捕獲源庫變更,或對接Kafka等消息隊列實現流式數據接入,確保數據能在秒級甚至毫秒級內可供查詢。
四、 在數據處理與存儲支持服務中的典型應用
憑借上述能力,分布式數據庫已成為現代數據處理與存儲支持服務的核心引擎,廣泛應用于:
- 互聯網與數字業務:支撐電商平臺的交易訂單、用戶行為日志存儲與實時商品推薦;支持社交媒體的海量用戶動態、消息流與即時搜索。
- 金融科技與風險管理:用于存儲全量交易流水,實現實時反欺詐檢測、信用風險實時評估和合規監控。
- 物聯網與智能制造:存儲來自海量傳感器和設備的時間序列數據,并實時監控設備狀態、預測性維護與分析生產效能。
- 企業級數據中臺:作為統一的數據湖或數據倉庫的底層存儲,整合多業務線數據,為BI分析、實時報表和用戶畫像提供高并發查詢服務。
分布式數據庫通過其創新的架構,成功地將海量數據存儲的“容量難題”與實時查詢的“速度挑戰”轉化為可管理、可擴展的技術方案。它不僅僅是存儲工具的升級,更是構建敏捷、智能的數據處理與存儲支持服務的戰略性基石。隨著云計算、人工智能的深度融合,分布式數據庫將繼續演進,以更強的彈性、更智能的自治管理和更豐富的實時分析能力,驅動各行各業的數字化轉型與數據價值釋放。
如若轉載,請注明出處:http://www.boobi.cn/product/18.html
更新時間:2026-06-13 14:58:47