TFRecords 高效的數(shù)據(jù)存儲格式與訓練數(shù)據(jù)處理支持服務
在現(xiàn)代機器學習和深度學習領域,尤其是在處理大規(guī)模數(shù)據(jù)集時,高效的數(shù)據(jù)存儲、讀取和處理流程對模型訓練的性能至關重要。TensorFlow生態(tài)系統(tǒng)中的TFRecords文件格式,正是為解決這一挑戰(zhàn)而設計的關鍵技術之一,它與配套的數(shù)據(jù)處理和存儲支持服務共同構成了一個強大的數(shù)據(jù)處理流水線。
一、TFRecords:TensorFlow的高效數(shù)據(jù)存儲格式
TFRecords是一種基于Google Protocol Buffers(protobuf)的二進制文件格式,專為TensorFlow設計,用于序列化存儲數(shù)據(jù)樣本。其主要優(yōu)勢在于:
- 高性能與高效存儲:二進制格式比純文本(如CSV、JSON)更緊湊,能顯著減少磁盤占用,并加快I/O讀取速度,這對于需要頻繁從磁盤加載數(shù)據(jù)的訓練過程尤為重要。
- 序列化存儲:它將每個數(shù)據(jù)樣本(如圖像及其標簽、文本序列等)序列化為
tf.train.Example或tf.train.SequenceExample協(xié)議緩沖區(qū)消息,然后順序存儲。這種結(jié)構便于TensorFlow高效地順序讀取,并天然支持并行化數(shù)據(jù)加載。 - 與TensorFlow原生集成:TFRecords與
tf.dataAPI無縫協(xié)作。tf.data.TFRecordDataset能夠輕松創(chuàng)建輸入流水線,支持并行讀取、預取、混洗和批處理,最大化GPU/TPU的利用率,避免I/O成為訓練瓶頸。 - 支持復雜數(shù)據(jù)結(jié)構:
tf.train.Example可以靈活存儲多種類型的數(shù)據(jù)(字節(jié)串、浮點數(shù)列表、整數(shù)列表等),非常適合存儲非結(jié)構化數(shù)據(jù)(如圖像、音頻)與結(jié)構化特征(如數(shù)值、分類標簽)的組合。
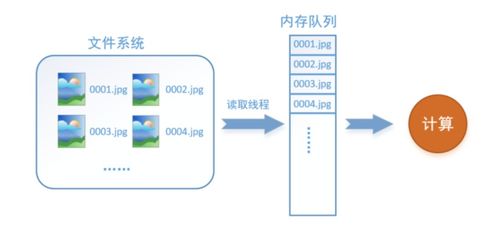
創(chuàng)建TFRecords文件通常涉及一個預處理步驟:將所有原始數(shù)據(jù)(如JPEG圖像)轉(zhuǎn)換、歸一化,并與標簽一起封裝成Example對象,然后寫入一個或多個TFRecord文件。
二、數(shù)據(jù)處理與存儲支持服務的完整生態(tài)
僅靠TFRecords格式本身是不夠的,一個健壯的機器學習項目需要一套完整的數(shù)據(jù)處理與存儲支持服務。這套服務通常涵蓋以下層面:
- 數(shù)據(jù)存儲與版本管理服務:
- 對象存儲:TFRecords文件通常存儲在高可用、可擴展的對象存儲服務中,如AWS S3、Google Cloud Storage (GCS)、阿里云OSS等。這些服務提供高吞吐量和持久性。
- 數(shù)據(jù)集版本控制:使用類似DVC(Data Version Control)、Pachyderm或LakeFS等工具對數(shù)據(jù)集(包括TFRecords文件)進行版本管理,確保實驗的可復現(xiàn)性,能夠追蹤每次訓練所使用的具體數(shù)據(jù)快照。
- 數(shù)據(jù)預處理與生成服務:
- ETL流水線:構建自動化的數(shù)據(jù)提取(Extract)、轉(zhuǎn)換(Transform)、加載(Load)流水線。該流水線負責從原始數(shù)據(jù)源讀取數(shù)據(jù),進行清洗、增強(如圖像翻轉(zhuǎn)、裁剪)、特征工程,并最終生成TFRecords文件。可以使用Apache Beam、TFX(TensorFlow Extended)的ExampleGen組件或Airflow等編排工具來實現(xiàn)。
- 數(shù)據(jù)增強:在生成TFRecords時或通過
tf.data流水線進行實時數(shù)據(jù)增強,以增加數(shù)據(jù)多樣性,提升模型泛化能力。
- 高性能數(shù)據(jù)讀取與傳輸服務(
tf.dataAPI):
- 這是連接TFRecords存儲與訓練計算的核心服務。
tf.dataAPI允許開發(fā)者構建復雜的輸入流水線,關鍵操作包括:
interleave:并行從多個TFRecords文件讀取數(shù)據(jù)。
shuffle:在內(nèi)存或文件級別對數(shù)據(jù)進行隨機化,打破樣本順序。
prefetch:在模型訓練當前批次時,異步預取下一批次數(shù)據(jù),實現(xiàn)計算與I/O的重疊。
map:應用預處理函數(shù)(如解碼圖像、歸一化)。
- 分布式讀取:在分布式訓練環(huán)境中,
tf.data服務可以協(xié)調(diào)多個worker節(jié)點從共享存儲中高效地讀取不同的數(shù)據(jù)分片。
- 數(shù)據(jù)驗證與質(zhì)量監(jiān)控服務:
- 在生成TFRecords前后,使用TFX的TensorFlow Data Validation (TFDV)等庫分析數(shù)據(jù)統(tǒng)計信息(如特征分布、缺失值),生成數(shù)據(jù)模式(Schema),并持續(xù)監(jiān)控訓練數(shù)據(jù)與服務數(shù)據(jù)之間的偏斜,確保數(shù)據(jù)質(zhì)量。
三、典型工作流程
一個集成了上述服務的典型工作流程如下:
- 原始數(shù)據(jù)收集:將原始數(shù)據(jù)(圖片、文本等)上傳至云存儲。
- 預處理與TFRecords生成:觸發(fā)數(shù)據(jù)處理流水線,進行清洗、增強,并批量寫入TFRecords文件,存儲于對象存儲中。同時進行數(shù)據(jù)驗證,生成Schema。
- 版本標記:使用數(shù)據(jù)版本控制工具對生成的TFRecords文件集打上版本標簽。
- 訓練流水線:訓練任務啟動時,根據(jù)指定的數(shù)據(jù)版本,從存儲中讀取TFRecords文件路徑。通過
tf.dataAPI構建高效的數(shù)據(jù)輸入流水線(包含并行讀取、混洗、批處理、預取),將數(shù)據(jù)源源不斷地供給訓練循環(huán)。 - 迭代與更新:當需要更新數(shù)據(jù)集或進行A/B測試時,重復上述過程,生成新版本的數(shù)據(jù)集,并啟動新的訓練任務。
結(jié)論
TFRecords作為TensorFlow生態(tài)中高效的序列化數(shù)據(jù)格式,是優(yōu)化訓練數(shù)據(jù)I/O的基石。要充分發(fā)揮其效能,必須將其嵌入一個完整的數(shù)據(jù)處理與存儲支持服務體系之中。這個體系涵蓋了從數(shù)據(jù)存儲、版本管理、預處理流水線到高性能讀取和數(shù)據(jù)質(zhì)量監(jiān)控的方方面面。通過整合這些服務,團隊能夠構建出可擴展、可復現(xiàn)且高性能的機器學習數(shù)據(jù)流水線,從而將更多精力聚焦于模型設計與算法創(chuàng)新,而非數(shù)據(jù)處理的復雜性上。
如若轉(zhuǎn)載,請注明出處:http://www.boobi.cn/product/12.html
更新時間:2026-06-13 05:25:02