淺談大數據之HDFS 數據處理與存儲支持的基石
在大數據技術生態系統中,Hadoop分布式文件系統(HDFS)扮演著數據處理與存儲支持服務的核心角色。作為Hadoop項目的基石,HDFS以其高容錯性、高吞吐量和處理海量數據的卓越能力,為現代大數據應用提供了堅實可靠的基礎。
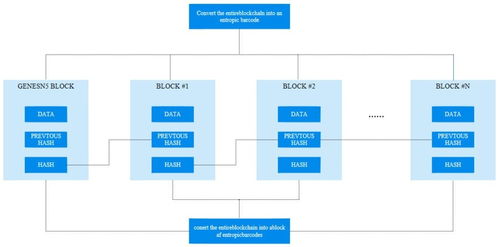
HDFS的設計哲學源于對“一次寫入,多次讀取”數據處理模式的深度優化。它將大規模數據集分割成多個數據塊,并分布式地存儲在由普通商用硬件組成的集群中。這種設計不僅降低了存儲成本,還通過數據冗余機制確保了數據的高可用性——每個數據塊默認會被復制到三個不同的節點上,即使某個節點發生故障,數據依然可以從其他副本中恢復,從而實現了出色的容錯能力。
在數據處理支持方面,HDFS采用“移動計算而非移動數據”的創新理念。傳統的集中式存儲系統在處理大數據時,需要將海量數據通過網絡傳輸到計算節點,這往往成為性能瓶頸。而HDFS允許計算任務被直接調度到存儲數據的節點上執行,極大減少了數據移動帶來的網絡開銷,顯著提升了數據處理效率。這種數據本地化特性使得HDFS特別適合批處理作業,如MapReduce計算框架,能夠在數據存儲的位置直接進行并行計算。
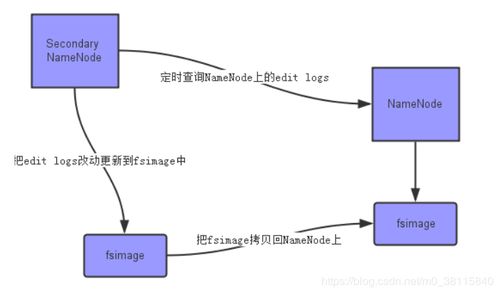
HDFS的存儲架構采用主從(Master/Slave)模式,由NameNode和DataNode兩種關鍵組件構成。NameNode作為主節點,負責管理文件系統的命名空間、訪問控制及數據塊到DataNode的映射關系;而多個DataNode作為從節點,實際存儲數據塊并處理客戶端的讀寫請求。這種清晰的職責分離使得系統既保持了強大的元數據管理能力,又實現了存儲容量的線性擴展——只需增加DataNode節點,就能輕松擴大存儲規模。
隨著大數據技術的發展,HDFS也在持續演進。從早期的主要支持流式數據訪問,到如今逐漸增強了對隨機訪問、小文件存儲和實時數據處理的支持。通過引入緩存機制、糾刪碼技術(Erasure Coding)以及與其他存儲系統(如對象存儲)的集成,HDFS正在不斷拓展其應用邊界,更好地適應云原生環境和多樣化的工作負載需求。
HDFS作為大數據處理與存儲的基礎服務,通過其獨特的分布式架構和設計理念,成功解決了海量數據存儲、高并發訪問和數據可靠性等關鍵挑戰。盡管面臨新型存儲系統的競爭,HDFS在大數據領域的基礎地位依然穩固,并繼續為各類數據分析、機器學習和大規模數據處理應用提供強有力的底層支持。理解HDFS的工作原理和特性,對于構建高效、可靠的大數據平臺至關重要。
如若轉載,請注明出處:http://www.boobi.cn/product/4.html
更新時間:2026-06-13 03:19:42